K8S-bug 排查之 kubeproxy 无法正常设置 iptables 了
😧 稀奇古怪的 bug 怎么这么多, 还好是一个前人遇到过的, 如果我是第一个发现的, 估计美好的周五晚上就没有了
1. 背景
即将下班的周五下午 5 点, 运维不合时宜的甩给我了一个图片, 这次好一些, 加了一段文字, 说用户做了下迁移, 然后发现服务启动后 redis 服务异常, 卸载重装大法也不好使,
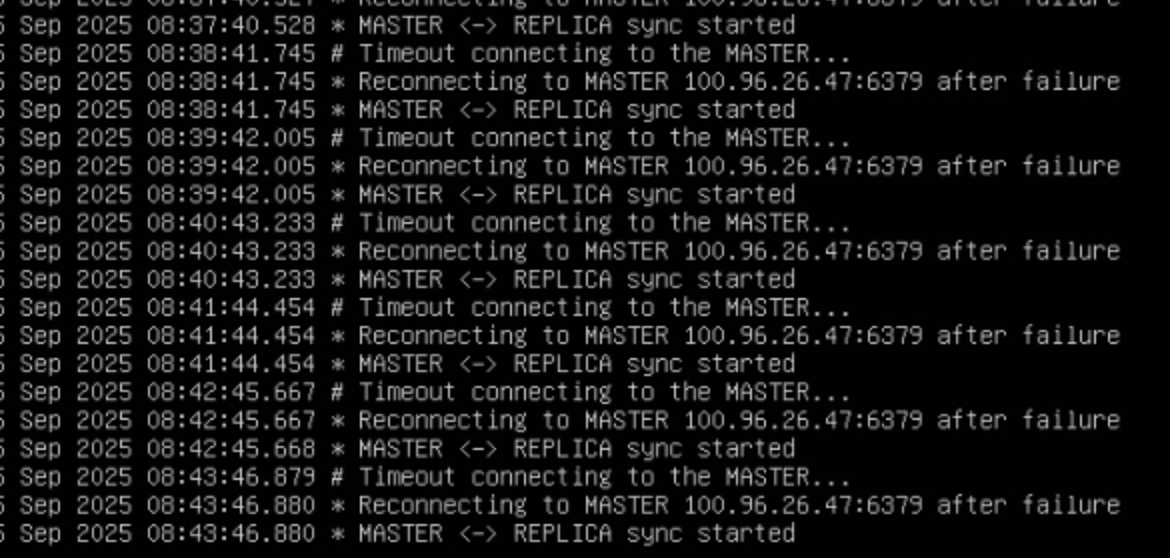
redis ha 使用 helm 部署的时候, 只有一个正常, 剩下的两个 redis pod 启动后无法连接到 master 的 redis pod.
环境说明
- 公司私有化部署到客户的 k8s 环境 v1.26
- 使用 redis-ha 部署 redis, 哨兵模式
2. 现象
- slave 的 redis pod 连接 redis 的时候使用 dns 解析的 redis cluster ip 有问题, 还是上一版本的 redis services ip
3. 逐步排查
起初怀疑是 dns 的问题, dns 记录没有更新,
新建 service 后 cluster ip 更新没有问题, 可以判断不是 dns 的问题
逐步检查 k8s 组件
检查到 kube proxy 节点的日志的之后, 发现日志中有错误, 发现节点上找不到 conntrack ipset 二进制文件, 原先设置的 ipvs 模式降级到了 iptables 模式了
conntrack ipset 二进制缺失
本来是没啥问题, iptables 就 iptables 吧, 毕竟服务没多少个, 性能是没啥问题的, 不过既然遇到了就先解决下
从其他地方拷贝 conntrack ipset 二进制后重启 kube-proxy. ipvsadm 检查后发现正常了
重启后发现报错变了, 一条日志占了半屏, 后面还有其他错误日志没发现, 这个错误消除后, 发现了可以定位 bug 的日志
兄弟们, 有时候就是这样, 你只看到了错误日志, 你以为找到了
解决问题的金手指但其实你看到的是个烟雾弹
1I1113 16:15:07.928773 1 proxier.go:1464] "Reloading service iptables data" numServices=0 numEndpoints=0 numFilterChains=4 numFilterRules=3 numNATChains=4 numNATRules=5
2E1113 16:15:07.931291 1 proxier.go:1481] "Failed to execute iptables-restore" err=<
3exit status 2: ip6tables-restore v1.8.4 (legacy): unknown option "--xor-mark"
4Error occurred at line: 16
5Try `ip6tables-restore -h' or 'ip6tables-restore --help' for more information.
6>
7I1113 16:15:07.931308 1 proxier.go:858] "Sync failed" retryingTime="30s"
8I1113 16:15:07.931317 1 proxier.go:820] "SyncProxyRules complete" elapsed="22.67239ms"
看到第一反应, unknown option "--xor-mark" iptables 版本太老的, 不支持这个命令, 或者 mod 没加载, 检查了一遍, 发现版本也是新的, ko mod 也加载了, 神奇, 而且日志中提示使用的确实是 1.8.4 版本的 iptables. 真见鬼了 兄弟们
随后我想着会不会就这样的呢? 这个看着是个 error, 其实是个 warning 呢? 毕竟服务连接 es 这些是正常的啊
反思, 不正常, 十分有十二分的不正常
回到问题原点
- 部署 redis
- redis-master 启动没有问题
- redis-slave1 启动没有问题
- redis-slave2 启动故障, 连接 master 提示超时,
- 登录到 slave2 机器上发现 telnet 确实不通, 查看 ipvs 确实没有条目, 确实是这个直接原因
分析, slave1 可以通过 cluster 连接到 redis master, slave2 发现连接不上, 首先证明 master 是没问题的, 还是 ipvs 条目创建的问题, ipvs 是由 kube proxy 直接管理的, 问题还是在 kubeproxy
- 尝试将业务服务移动到 master 试一下, 因为出现问题的都在两台 worker 节点上,
- 将这两台机器 cordon 后, 删了业务 pod
- 原先启动报错连接不到 redis, 移动后可以正常启动了
- 检查现在移动到的这个节点和之前有问题的节点有什么不一致的
- 部署服务全部都是一致的, 但是正常机器是没有报 ip6tables-restore 这个错误的
- 不经意对比到内核版本的时候发现问题了

找到一个十分像问题点的不同, 内核版本有差别
4. 定位原因
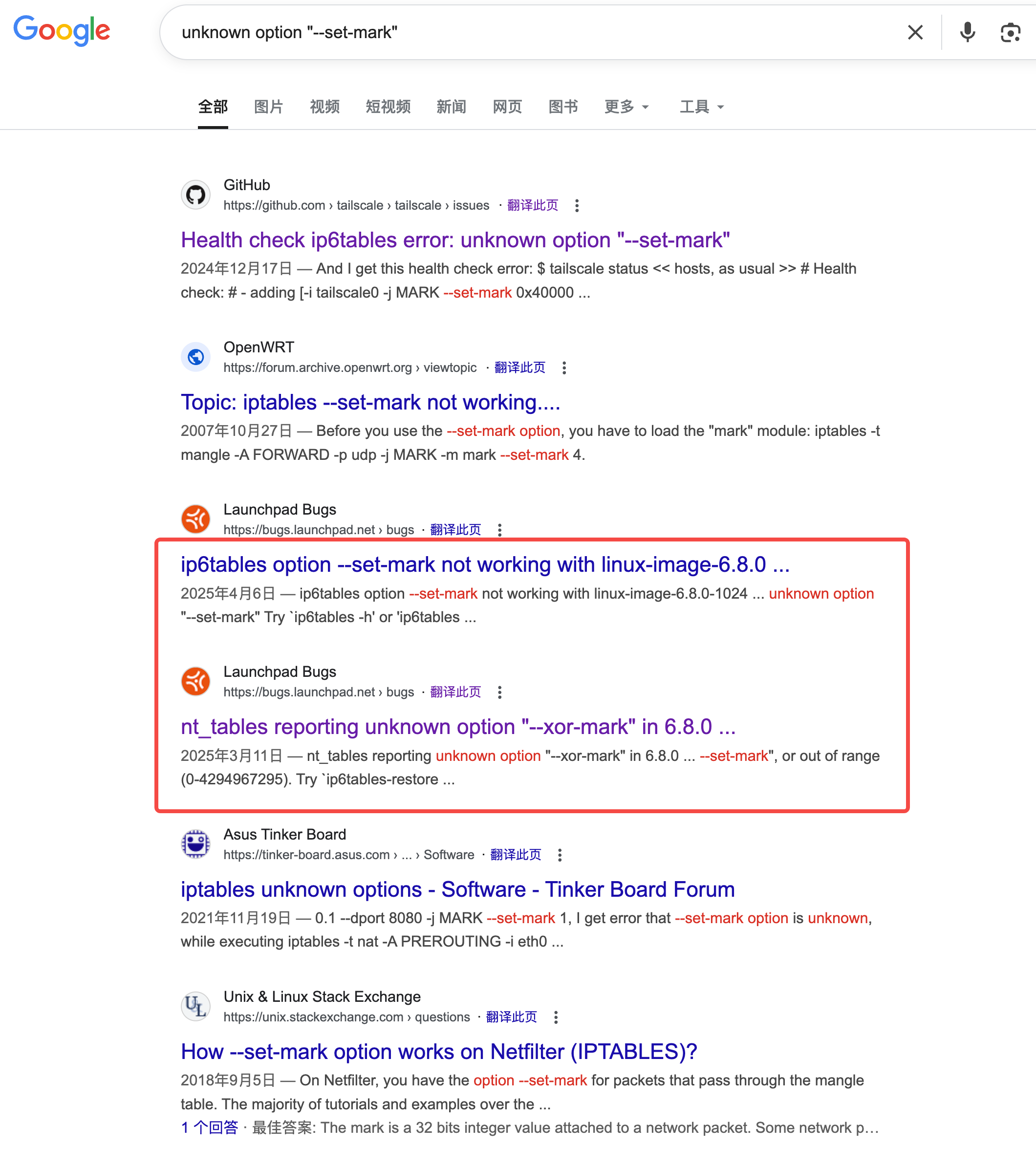
google 大法
unknown option “–set-mark” 发现确实好像有些眉目额, 难道就是内核的 bug 吗 ?
确实是的, 内核的锅, 上一年 12 月, 也算是一个新鲜的 bug, 这种事为什么发生在我身上, 我是易 bug 体质吗?
根本原因(Root Cause):一个有缺陷的内核提交
报告中明确指出了导致这个问题的“罪魁祸首”:一个特定的内核提交(commit)。
- Commit ID: 862c95d9859f
- Commit 标题: netfilter: xt_mark: reject MARK target with mask
这个提交的意图本来是好的,但实现是错误的。 - 原本的意图: 该提交的作者可能想要增加一个检查,以防止用户设置一个无效的 mark/mask 组合。例如,–set-mark 0x10/0x1 就是无效的,因为 mark 的值 (0x10) 中包含的位超出了掩码 (0x1) 的范围。
- 错误的结果: 然而,代码的实现过于“激进”和简单粗暴,它直接禁止了所有使用掩码的 MARK 目标,无论这个组合是否有效。这破坏了一个已经存在了很长时间并且被广泛使用的合法功能。
这是一个典型的回归 Bug (Regression Bug):为了修复或改进某个东西而引入的新代码,却意外地破坏了另一个原本正常工作的功能
影响范围
这个 Bug 的影响非常广泛,因为它从内核层面直接禁用了 MARK 目标的一个核心功能。
- Kubernetes (K8s): kube-proxy 在 IPVS 模式下严重依赖 –set-mark 0x4000/0x4000 这样的语法来标记需要做 SNAT 的流量。当内核拒绝这条规则时,kube-proxy 的同步循环就会失败,导致其陷入 CrashLoopBackOff。
- Tailscale: 正如报告中提到的,Tailscale 也使用类似的规则来标记流量,因此也会在这个有问题的内核版本上运行失败。
- 其他网络软件: 任何依赖 iptables mark 掩码功能的防火墙脚本、网络工具或 CNI 插件都会受到影响。
- 受影响的系统:
- Ubuntu 24.04 (Noble Numbat),因为它默认搭载了受影响的 Linux 6.8 内核。
- Ubuntu 22.04 LTS (Jammy Jellyfish) 等旧版本,如果用户安装了 HWE (Hardware Enablement) 内核,内核版本也会升级到受影响的版本,从而引入这个问题。
5. 分析日志出错点
1 // --------------------------------------------------------------------------
2 // 应用变更到系统
3 // --------------------------------------------------------------------------
4
5 // 将内存中 `activeEntries` 的变更同步到 ipset 内核中。
6 // 这个函数会计算差异,并调用 `ipset` 命令来添加或删除条目。
7 for _, set := range proxier.ipsetList {
8 set.syncIPSetEntries()
9 }
10
11 // 为 ipset 生成相关的 iptables 规则 (例如,匹配 ipset 的规则)。
12 proxier.writeIptablesRules()
13
14 // 准备最终的 iptables-restore 数据。
15 proxier.iptablesData.Reset()
16 proxier.iptablesData.Write(proxier.natChains.Bytes())
17 proxier.iptablesData.Write(proxier.natRules.Bytes())
18 proxier.iptablesData.Write(proxier.filterChains.Bytes())
19 proxier.iptablesData.Write(proxier.filterRules.Bytes())
20
21 klog.V(5).Infof("Restoring iptables rules: %s", proxier.iptablesData.Bytes())
22 // 这是整个 iptables 同步过程中最核心的原子操作。
23 // 所有之前在内存中构建好的 iptables 规则(存储在 proxier.iptablesData 中)
24 // 通过 `iptables-restore` 命令一次性、原子地应用到系统中。
25 // `utiliptables.NoFlushTables` 选项告诉 `iptables-restore` 不要清除表中已有的、非 kube-proxy 管理的规则。
26 err = proxier.iptables.RestoreAll(proxier.iptablesData.Bytes(), utiliptables.NoFlushTables, utiliptables.RestoreCounters)
27 if err != nil {
28 klog.Errorf("Failed to execute iptables-restore: %v\nRules:\n%s", err, proxier.iptablesData.Bytes())
29 // 如果 iptables-restore 失败,需要回滚新打开的端口,以避免资源泄漏。
30 utilproxy.RevertPorts(replacementPortsMap, proxier.portsMap)
31 return
32 }
6. 解决方法
由于我没有直接接触客户, 不过用脚趾头想了下, 用户说的迁移, 其实是偷偷升级了 linux 内核, 但是升级操作还不统一, 小版本不一致, 所以造成了 master 的内核是好的, worker 节点的内核是 bug 版本的
反馈给客户了, 让用户升级内核解决了
参考链接
https://github.com/rancher/rke2/issues/7438
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/2091990
https://github.com/kubernetes/kubernetes/blob/v1.14.10/pkg/proxy/ipvs/proxier.go#L721