实战-Windows 下 golang 进程无法被 kill 排查.md
1. 背景
这次遇到的是一个很恶心的 Windows 现场问题:
- 业务进程长时间不再上报心跳
- 监控 goroutine 也不再推进
- 任务管理器里进程无法结束,提示“拒绝访问”
- 服务重启后,新的 updater 进程还能继续拉起来,但旧进程并没有真正退出
- 卸载流程也会被卡住
第一眼看上去像是用户态程序写炸了:死循环、锁没释放、goroutine 卡死、或者 panic 被吞了。
但这条路越查越不对。最后定位到的根因并不在普通 Go 逻辑里,而是在 WinPcap 的 NPF 驱动路径上。
更准确地说:结合复现实验、用户态/内核态堆栈、以及公开讨论,可以把问题收敛到旧版 NPF 驱动在并发枚举网卡时卡死,进而把调用线程拖进内核态等待。
这篇文章把完整排查路径整理一下,顺便把当时用到的一套 Windows 调试工具链也记下来。
2. 现象
现场现象非常稳定:
- 心跳日志停止
- monitor 日志停止
- 相关采集组件因为配置错误无法正常启动
- 在任务管理器中手动结束进程失败
- 服务重启后出现多个 updater 实例
- 卸载失败
这里最容易误判的一点是:“无法结束进程”不一定是用户态没处理退出信号,也可能是线程已经陷进内核态等待,导致用户态 kill 不了。
3. 复现条件
复现方式并不复杂,核心是把问题逼到“并发枚举网卡 + 异常重试”这个路径:
- 同时打开多个依赖抓包/网卡枚举的模块
- 人为制造配置错误,让相关组件持续启动失败
- 让 supervisor/updater 不断重试
复现后可以看到一个明显的时间线:
- 初期心跳、监控都正常
- 一段时间后心跳先停
- 再过一段时间 monitor 也停
- 最后任务管理器已经无法结束进程
这个顺序很关键:它说明不是程序瞬间整体崩掉,而是某条关键执行链路先卡死,之后连带把其他逻辑慢慢拖死。
4. 第一轮误判:以为是 goroutine 自己死了
一开始很自然会怀疑:
- 心跳 goroutine panic 了
- 某个死循环把 CPU 吃满了
- 某个锁没放,导致心跳和 monitor 都在等
但实际现象和这种判断对不上:
- 没看到 panic 日志
- 不是 CPU 飙升型问题
- 不是所有 goroutine 同时消失,而是“有的停了,有的还活着”
这时候要把问题拆开看:
- 业务逻辑有没有退出?
- 线程有没有卡在 syscall/cgo?
- 调用栈有没有进入内核驱动?
如果第三个成立,那就不是普通 Go 代码层面能解释干净的事了。
5. 先用 pprof 看用户态,再决定要不要下内核态
按照 Go 官方文档,挂 pprof 最快的方式就是直接引入 net/http/pprof,然后起一个 HTTP 服务:
1import (
2 _ "net/http/pprof"
3 "log"
4 "net/http"
5)
6
7func NewProfileHTTPServer(addr string) {
8 go func() {
9 log.Println(http.ListenAndServe(addr, nil))
10 }()
11}
我现场一般会直接挂一个只在内网开放的端口,然后重点看:
/debug/pprof/goroutine/debug/pprof/heap/debug/pprof/profile
这一步的作用不是“直接证明驱动死锁”,而是先回答两个问题:
- Go 进程是不是还活着
- 哪些 goroutine 停在 syscall/IO/等待链路上
如果 pprof 还能打开,但业务 goroutine 不再推进,这通常意味着:进程还没完全死,只是关键执行链路已经卡住。
6. 为什么进入死锁后,有的协程会卡死,有的不会
这是这类问题里最容易让人困惑的点。
先说结论:进入内核态卡死的,不是整个 Go runtime 瞬间“全停”,而是某些 goroutine 所在的执行链路先停。其他 goroutine 是否还能继续推进,取决于它们是不是依赖这条链路、有没有可用的 P/M、以及是否被共享锁/共享状态串住。
可以这样理解:
- 调用
pcapFindAllDevs这类路径时,Go goroutine 最终会落到 syscall/cgo 边界 - 如果对应线程长期阻塞在内核态,运行时不一定会把所有 goroutine 一起拖死
- 但如果这个 goroutine 持有关键锁、占着 supervisor 流程、或者后续很多逻辑都依赖它返回,那业务表象就会变成“越来越多的协程停摆”
所以你会看到一种典型现象:
pprof还能通- 某些 HTTP/日志协程还活着
- 心跳/monitor/拉起流程已经不动了
这不是矛盾,而是阻塞发生在关键链路,而不是所有 goroutine 同时被 runtime 停掉。
7. 把可疑点收敛到 pcapFindAllDevs
当我把视角从“业务 goroutine 为什么停了”切到“哪些系统调用可能把线程拖进内核态”以后,嫌疑点很快收敛到了网卡枚举逻辑。
因为现场里有一段路径会反复获取本机网卡列表,而这条路径最终会走到 WinPcap/Npcap 的设备枚举接口。
下面这张图就是当时直接定位到的关键调用点:
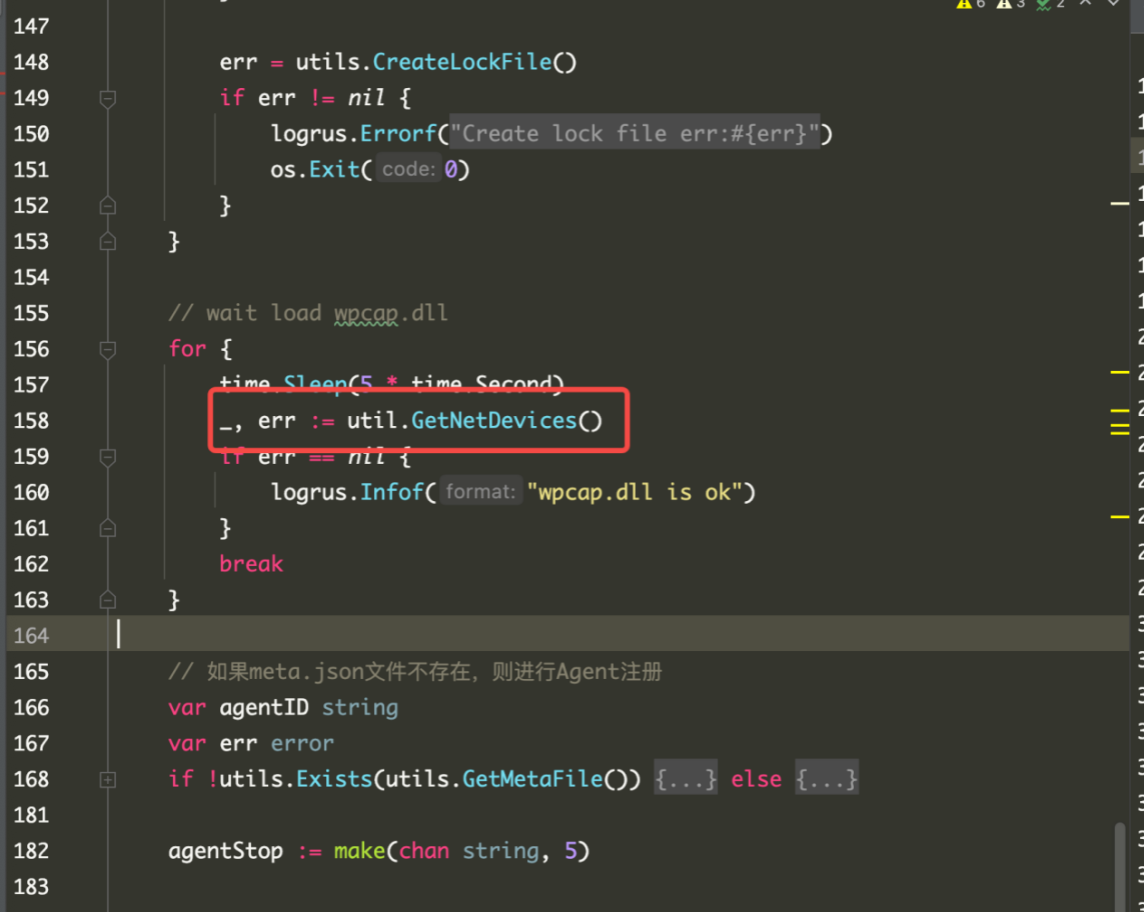
重点不是这段 Go 封装本身,而是它后面调用的 pcapFindAllDevs 最终会进入 NPF 驱动路径。
为了把猜测变成证据,我又单独写了最小复现程序,只保留:
- 启动
pprof - 调一次网卡枚举
- 输出设备信息
如果把业务逻辑剥干净后仍然能复现“进程无法结束”,那基本可以排除“上层业务代码”的锅。
8. 用户态证据不够,就下到内核态
这类问题只看普通日志已经不够了,后面我主要用了这几个工具:
Process Explorer:快速看线程、句柄、基本堆栈LiveKD:不重启机器,直接对在线系统做内核态查看WinDbg/CDB:看线程栈、IRP、符号、反汇编
其中 LiveKD 很适合这种“现场还活着,但不好重启”的问题。它可以把当前系统状态直接切进去看。
9. LiveKD / WinDbg 看到的关键信号
一旦把线程栈拉出来,问题的味道就完全变了。
下面这张图里,关键调用链已经非常清楚:
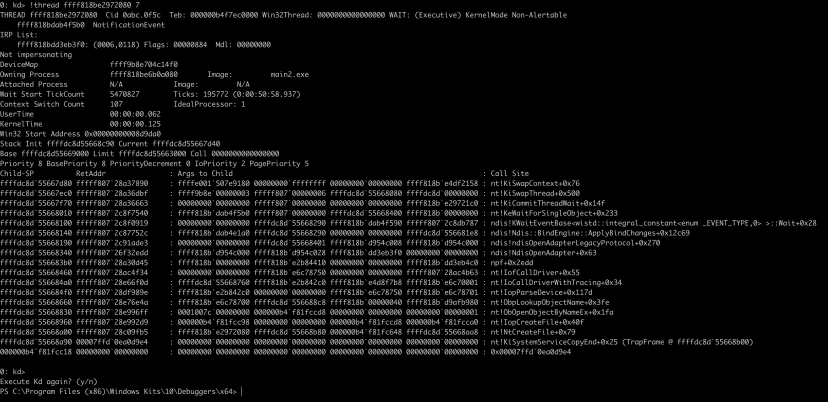
核心信号有三个:
- 线程处于
KernelMode等待态 - 调用链里出现了
ndis!ndisOpenAdapterLegacyProtocol - 调用栈继续往下能看到
npf路径
如果再看 IRP,可以进一步看到请求挂在 \Driver\npf 上。
这时候问题已经不太像“用户态进程结束不掉”,而更像:
线程在尝试打开/绑定网卡相关对象时,卡在了 NDIS + NPF 这条驱动链路里。
10. 一个很容易踩的坑:符号没配好,WinDbg 会直接误导你
如果 WinDbg 符号不对,很多分析命令会直接给你一堆假信息,典型报错就是:
OS symbols are WRONGEither you specified an unqualified symbol...
我现场是这么配的:
如果你用 cdb 或 windbg,也可以先把公共符号服务器环境变量配上:
1set _NT_SYMBOL_PATH=srv*DownstreamStore*https://msdl.microsoft.com/download/symbols
这一步看起来很基础,但在实际排障里非常关键。符号不对,后面所有 !analyze -v、线程栈、模块分析都会跑偏。
11. 为什么怀疑是旧版 NPF 驱动,而不是普通业务 bug
这里我没有把话说成“官方已经 100% 盖棺定论”,因为能拿到的最硬证据来自三部分:
- 复现实验:最小化程序也能复现
- 内核态调用栈:线程稳定挂在
ndisOpenAdapterLegacyProtocol和npf路径 - 公开讨论:旧 WinPcap/legacy NDIS 路径确实长期有兼容性和维护问题,Npcap 官方也明确说明它是 WinPcap 的更新/替代实现,且基于更新的 NDIS 6 LWF 架构
Npcap 官方站点给出的口径很明确:
WinPcap已长期不再维护Npcap是 Nmap Project 维护的替代实现Npcap在 Windows 7 及以后使用的是NDIS 6LWF,而不是 WinPcap 的旧NDIS 5路径
另外,公开社区里也能找到针对旧 NDIS/legacy bind 路径的讨论。下面这张图就是当时排查时对上的一条公开信息:
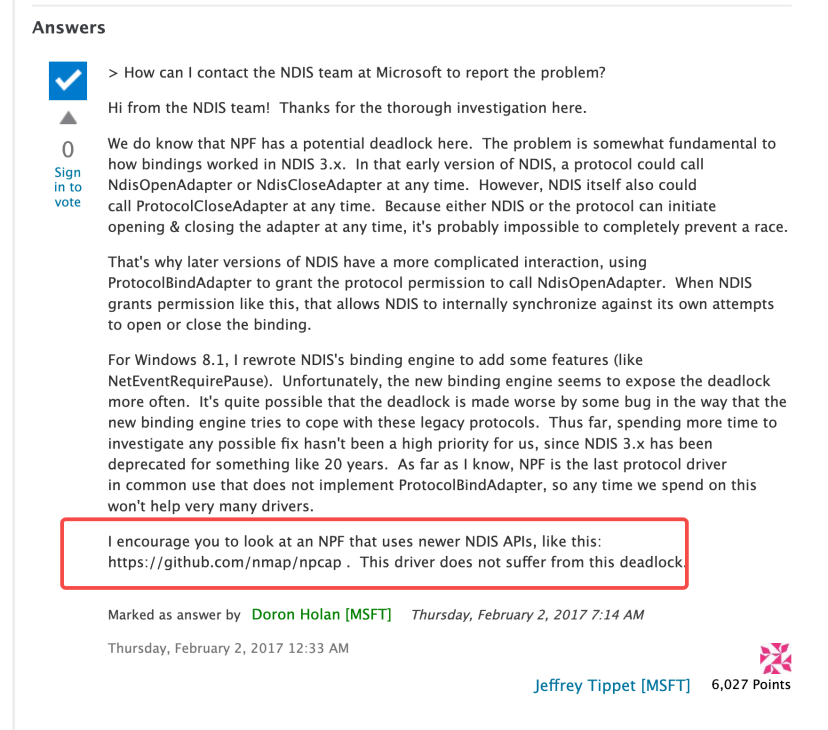
所以更稳妥的表述是:
结合复现、线程栈和公开资料,问题高度怀疑与旧版 WinPcap
NPF驱动在并发枚举网卡时卡在 legacy bind/open adapter 路径有关;迁移到Npcap或避免并发枚举网卡,是合理且可验证的修复方向。
12. 最终结论
这次问题的根因可以收敛成一句话:
多个执行路径并发调用网卡枚举接口,最终进入旧版 WinPcap NPF 驱动路径;线程卡在内核态等待后,相关进程表现为无法结束,依赖这条链路的心跳、monitor 和拉起逻辑也随之停摆。
这里最坑的点在于:
- 现象看起来像“Go 协程死了”
- 实际上根因落在驱动路径
- 用户态日志只能看到结果,看不到真正的阻塞点
13. 修复方向
我认为有两条修复路线,优先级很明确。
13.1 优先方案:迁移到 Npcap
这是我更推荐的方案,原因很直接:
WinPcap已经是停止维护状态Npcap仍在持续更新Npcap官方明确提供WinPcap API-compatible mode- 从架构上看,Npcap 也已经不是老 WinPcap 那条陈旧驱动路径
如果你的程序当前只是用 wpcap.dll/Packet.dll 兼容接口,迁移成本通常比重写业务逻辑低。
13.2 保守方案:避免并发枚举网卡
如果短期内没法替换驱动,那至少要先把触发条件拆掉:
- 不要让多个模块并发调用网卡枚举
- 把枚举网卡做成单飞或全局串行化
- updater 不要重复去探测同一类设备状态
- 在 supervisor 层面对异常重试做节流,避免错误配置把驱动路径持续打爆
说白了,这类问题在旧驱动路径上不是“多试几次总会成功”,而是越重试越容易把系统带进更糟糕的状态。
14. 我会保留的一套现场排障顺序
下次再遇到“Windows 进程无法结束 + Go 程序部分逻辑停摆 + 怀疑抓包驱动”这类问题,我会直接按这套顺序走:
- 先挂
pprof:确认用户态还有哪些 goroutine 在推进 - 再看 Process Explorer:确认线程、句柄、基础堆栈
- 必要时上 LiveKD:把线程状态、IRP、内核栈拉出来
- 最后用 WinDbg/CDB + 公共符号:确认模块、符号、调用路径
- 把业务代码最小化复现:隔离出是不是单纯的驱动/系统调用问题
这条链路的价值在于:先用低成本工具快速排除业务 bug,再用内核态证据确认是否已经掉进驱动层。
15. 参考链接
官方文档
- Process Explorer
- LiveKD
- Windows Debugger
- Microsoft public symbols
- Npcap 官网
- Npcap User’s Guide
- Npcap vs WinPcap
- WinPcap FAQ
- Go net/http/pprof